This is how you can make Clojure code more pleasant to work with:
Don’t use “use”
And don’t :refer anything either. Every var you bring from another namespace should have a namespace qualifier. Makes it easier to track vars to their source.
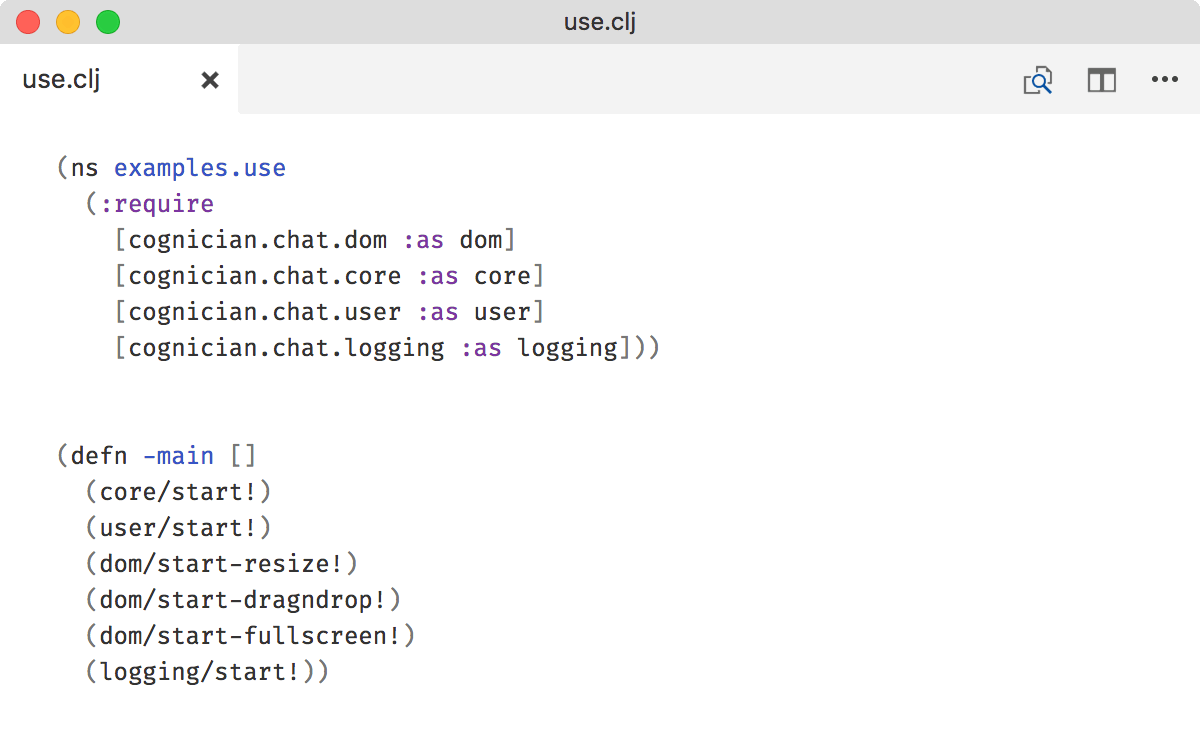
You’ll also save yourself from name collisions down the way.
Use consistent, unique namespace aliases
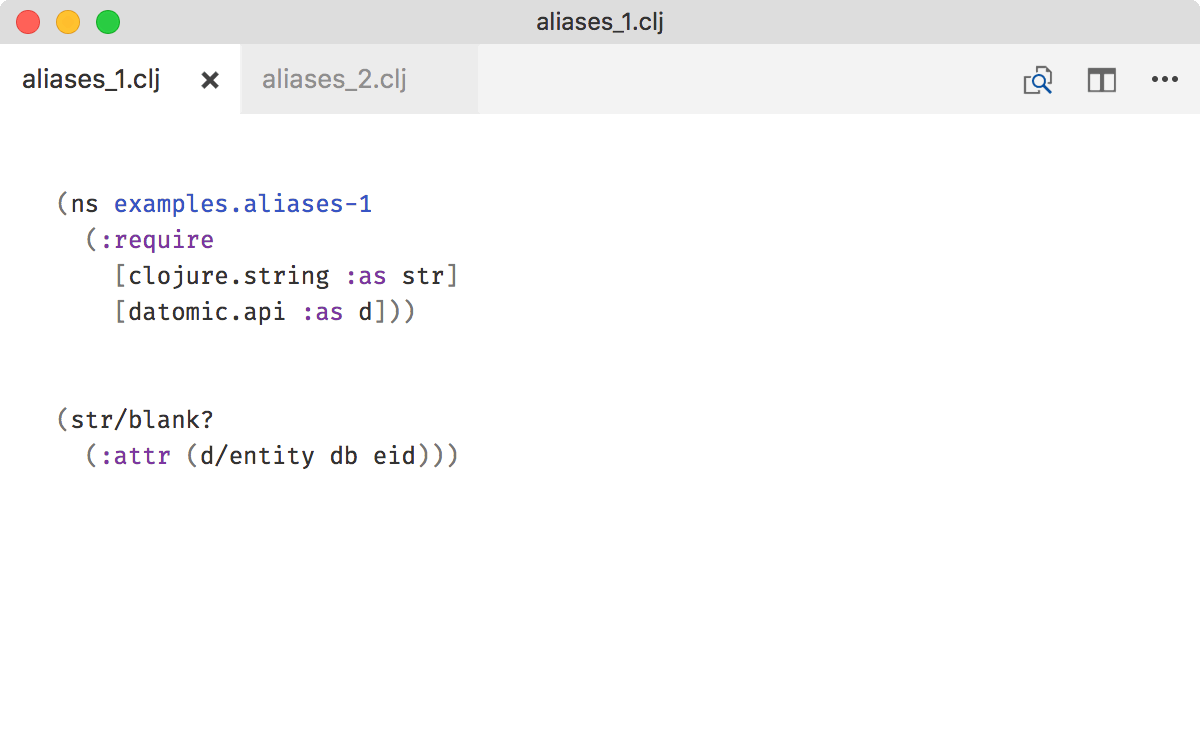
If you gave namespace an alias, stick to it. Don’t require
in one file but
[clojure.string :as string]
in another.
That way you’ll be able to actually remember your aliases. Oh, and grep starts to work.
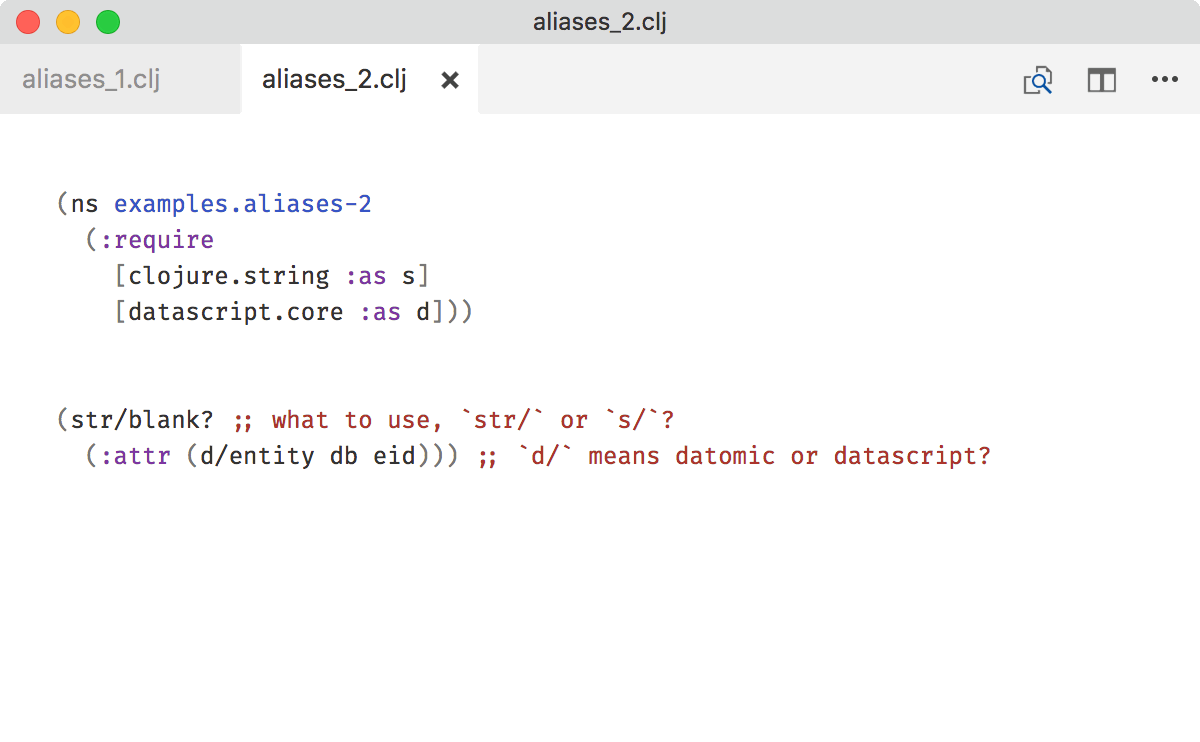
Keep aliases unique too. If d/entity could mean both datomic.api/entity or datascript.core/entity, you lose all the benefits of this rule.
Use long namespace aliases
Aliases should be readable on their own. Therefore
- don’t use single-letter aliases,
- don’t be clever or inventive,
- when shortening, only remove the most obvious parts (company prefix, project name,
clojure.*,coresuffix etc), - leave everything else intact:
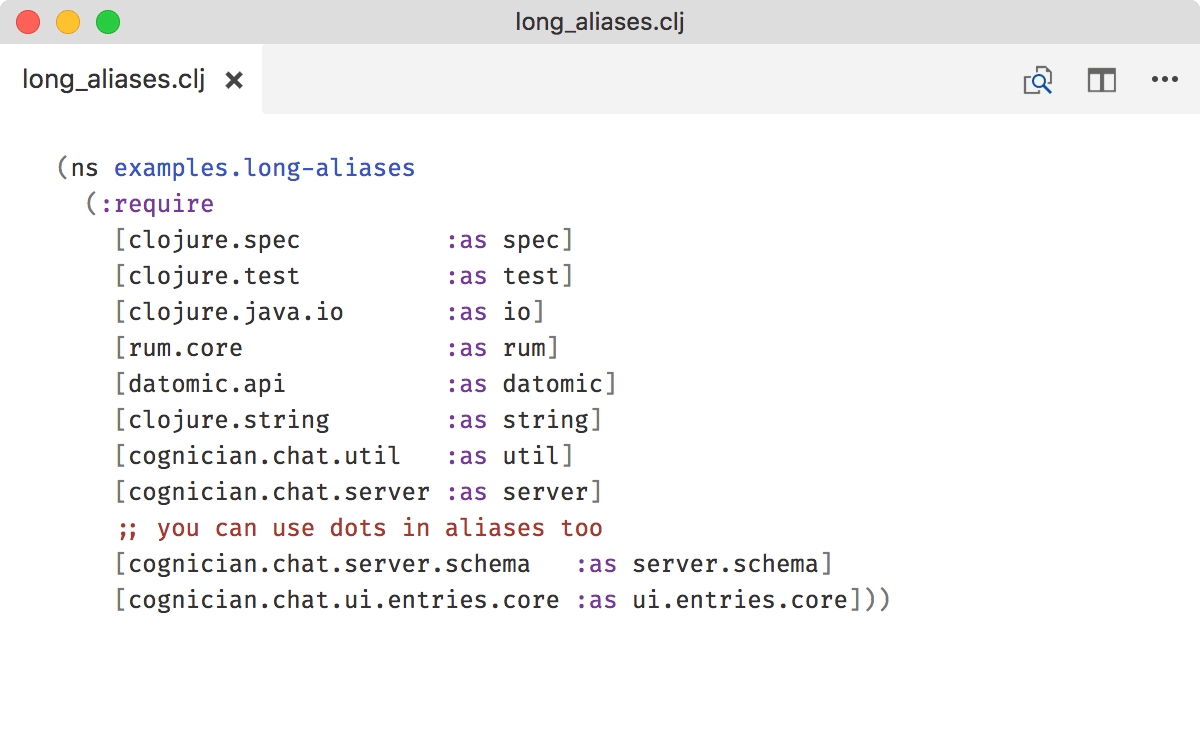
Now you can read your code starting from any place and don’t have to remember what maps to what. Compare
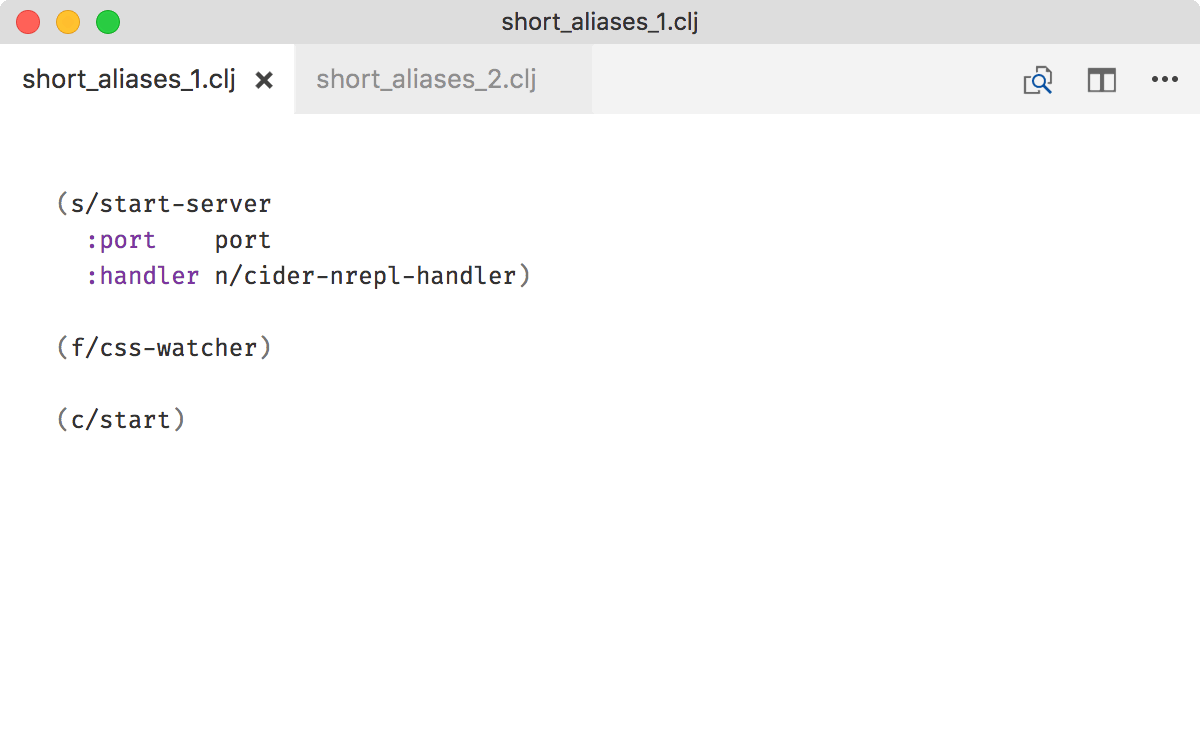
with
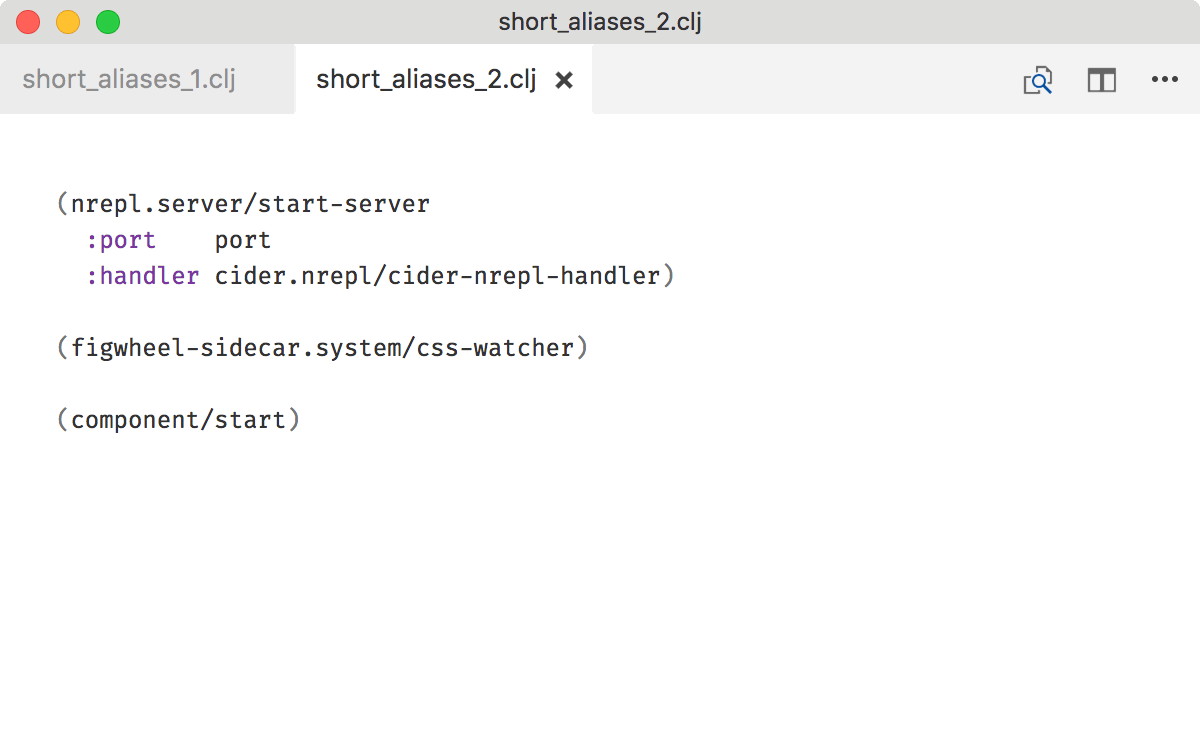
The former looks terser, but it’s hard to tell what’s going on. The latter is a bit longer but immediately communicates which systems are in play.
Another benefit: you’ll naturally tend to use aliases less often if they are long and clumsy, so long aliases will force you to organize your code better.
Choose readability over compactness
Clojure has a plethora of ways to write dense code. Don’t use them just because they are there. Always put readability and code clarity first. Sometimes it means even going against Clojure idioms.
An example. To understand this piece of code you need to know that possible-states is a set:
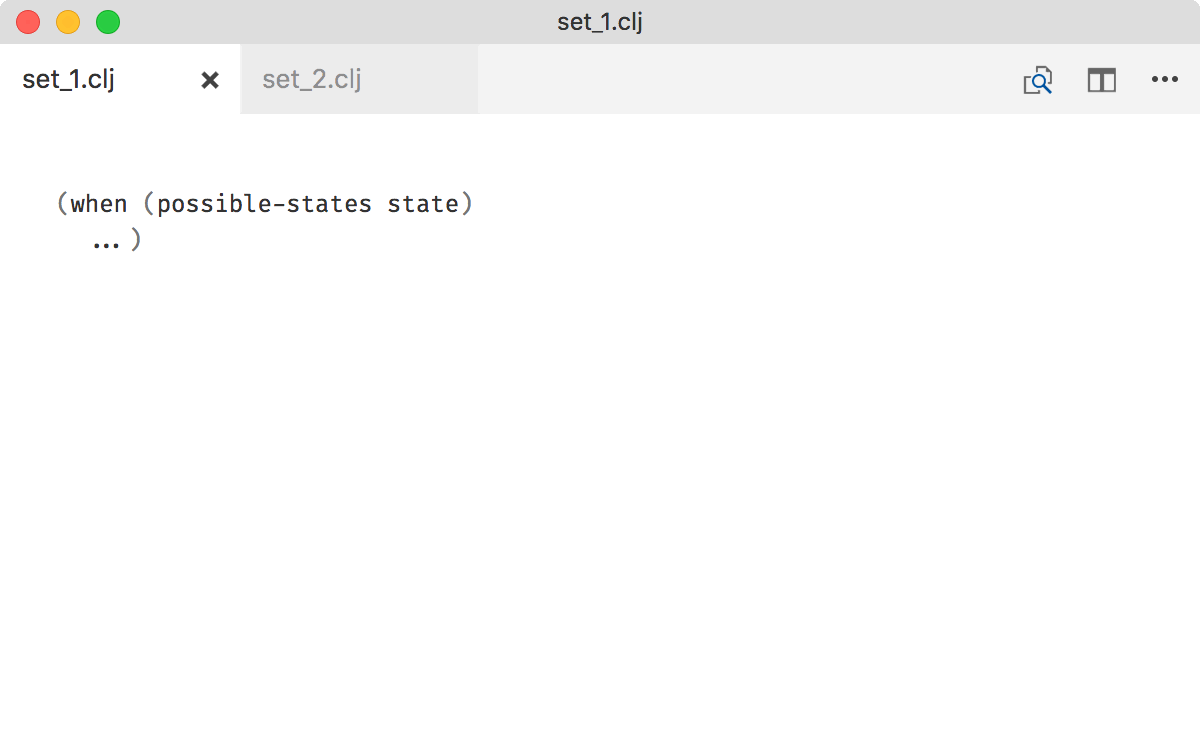
By contrast, to understand following code you don’t need any context:
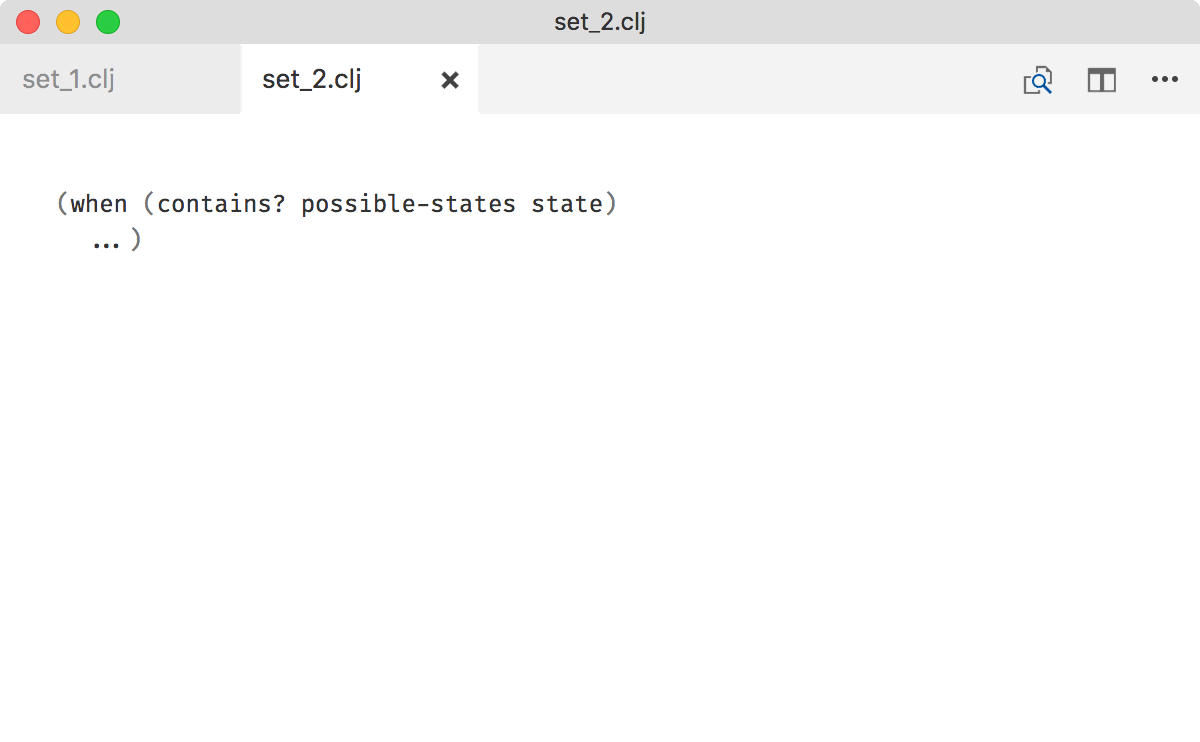
Also, notice how the latter reads almost like plain English.
My (incomplete) set of personal rules:
- use
contains?instead of using sets as functions, - use
getinstead of using map as a function, - prefer
(not (empty? coll))over(seq coll), - explicitly check for
nil?/some?(more on that below).
Don’t rely on implicit nil-to-false coercion
Unfortunately, Clojure mixes two very different domains: nil/existence checking and boolean operations. As a result, you have to constantly guess author’s intents because they’re not expressed explicitly in the code.
I advise using real boolean expressions and predicates in all boolean contexts. Explicit checks are easier to read and communicate intent better. Compare implicit

and explicit

The more serious reason is that nil-as-false idiom fails when you want false to be a possible value.
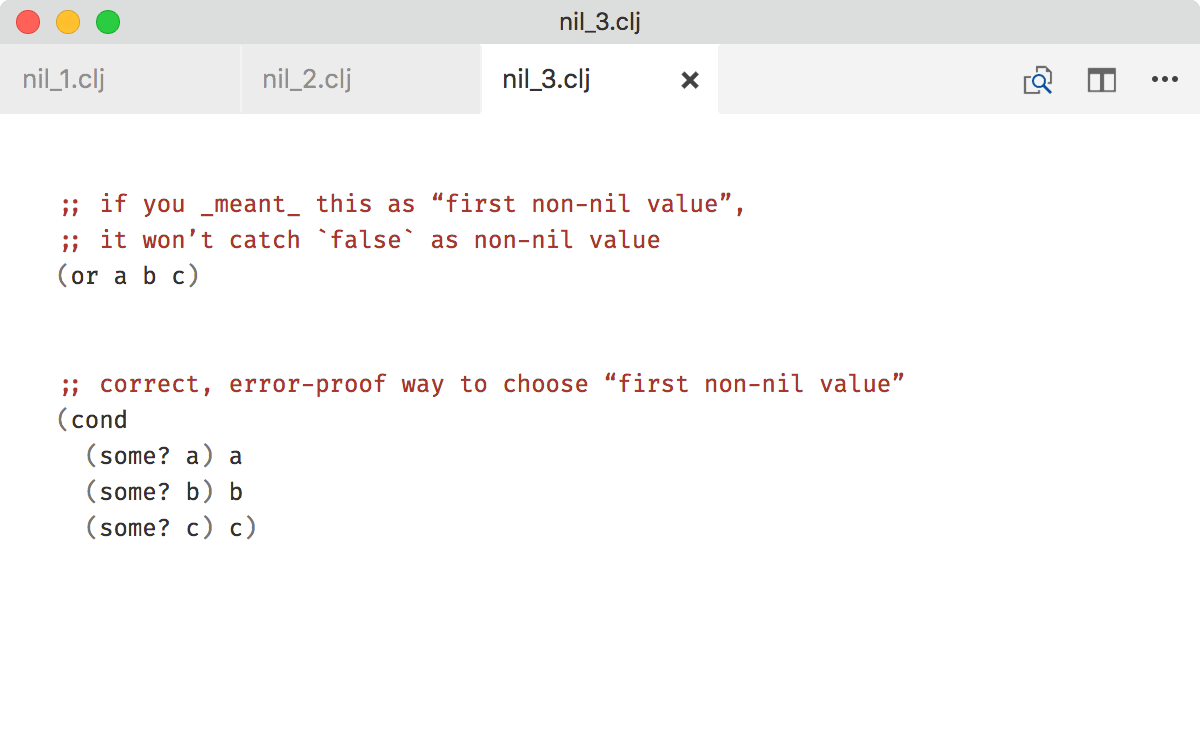
Problems like this are common when working with boolean attributes/parameters and default values.
Some advice to follow:
- wrap plain objects with
some?inwhen/if, - prefer
when-some/if-someoverwhen-let/if-let, - be careful with
orwhen choosing a first non-nil value, - for
filter/removepredicates, provide proper boolean values throughsome?/nil?.
Avoid higher-order functions
I found code that builds functions with comp, partial, complement, every-pred, some-fn to be hard to read. Mainly because it looks different from the normal function calls: no parens, application order is different, you can’t see arguments.
It requires effort to figure out what exactly will happen:
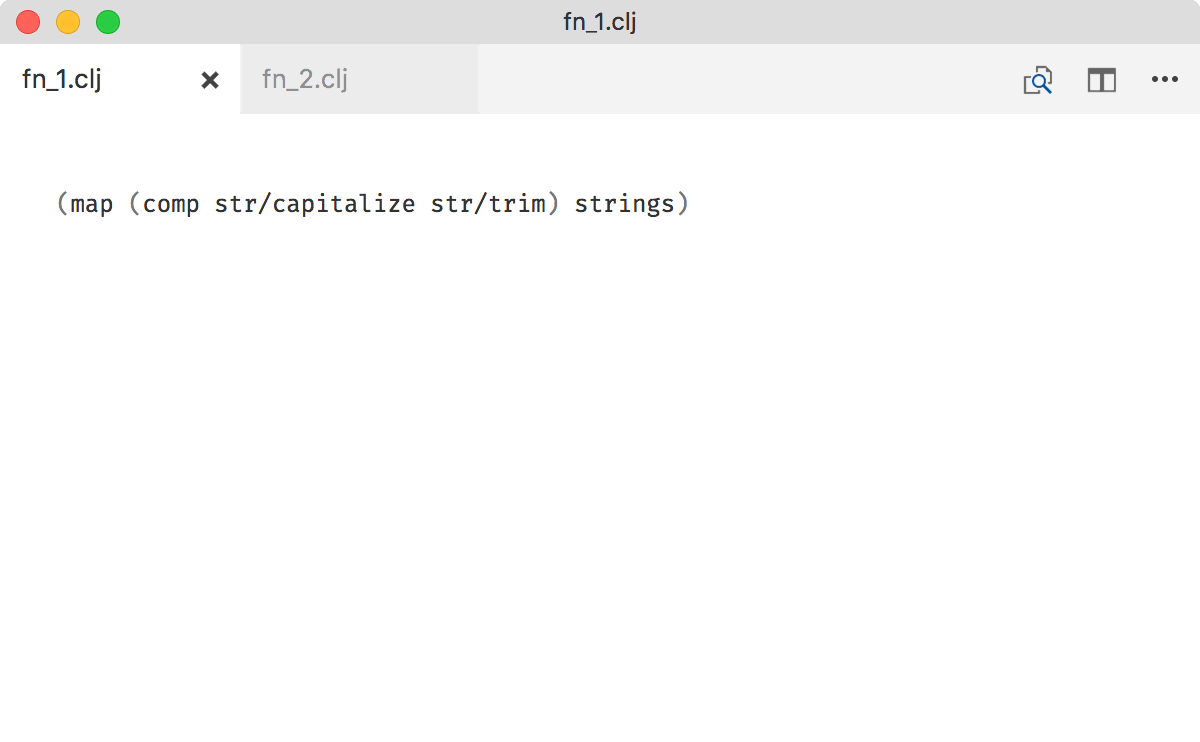
Even as experienced Clojure programmer I haven’t developed a skill to parse such structures easily.
What I find easy to read, though, is anonymous function syntax. It looks exactly like a normal function call, you can see where parameters go, what’s applied after what — it’s instantly familiar:
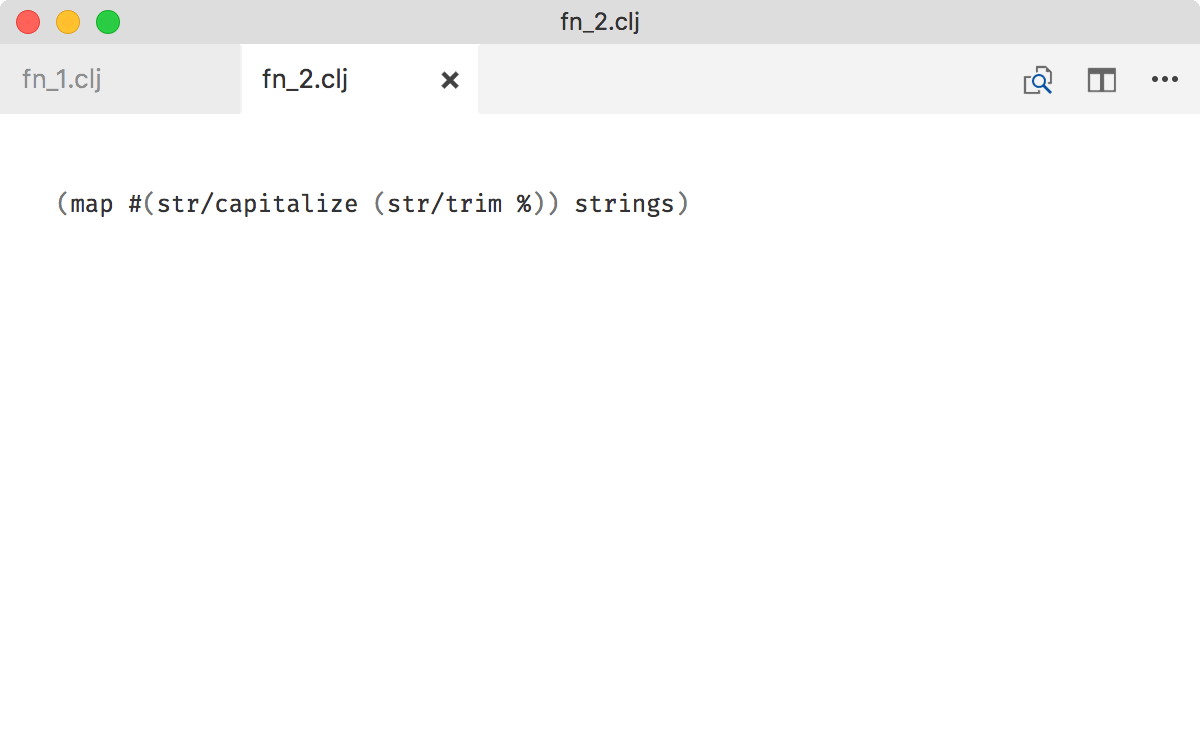
Don’t spare names
Some facilities in Clojure (threading macros, anonymous functions, destructuring, higher-order functions) were designed to let you skip names:
This is great but sometimes impedes readability. Without names, you are forced to keep all the intermediate results in your head.
To avoid that, add meaningful names where they could be omitted:
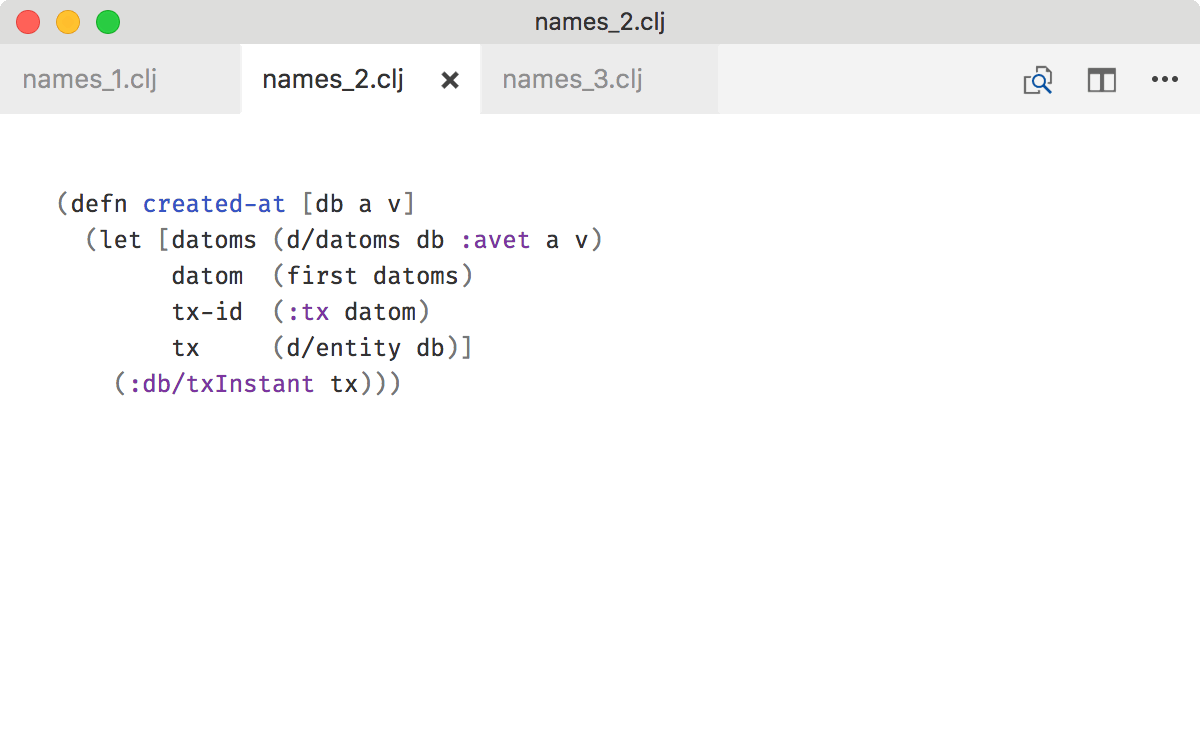
You can omit names in threading macros (->, ->> etc) but only if object/objects passed through do not change their type. Most cases of filtering, removing, modifying elements in a collection are fine.
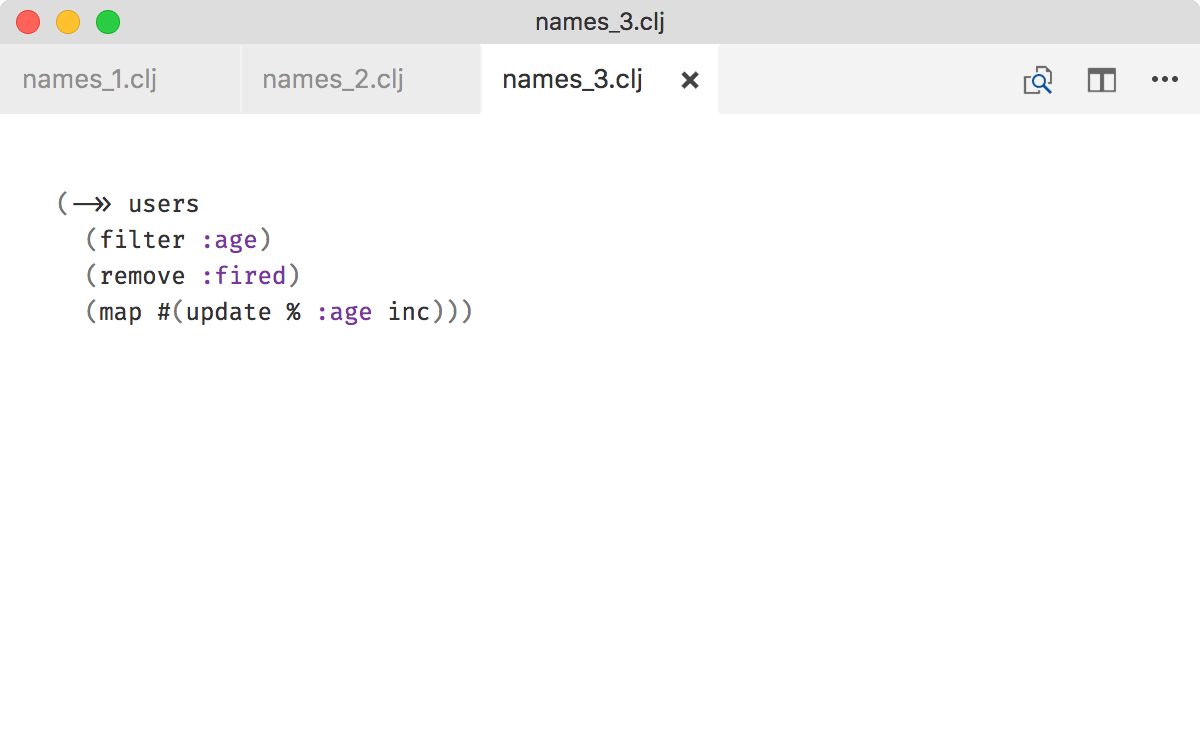
E.g. here because it’s still users all the way until the end, intermediate names can be omitted:
Don’t use first/second/nth to unpack tuples
Although this works:
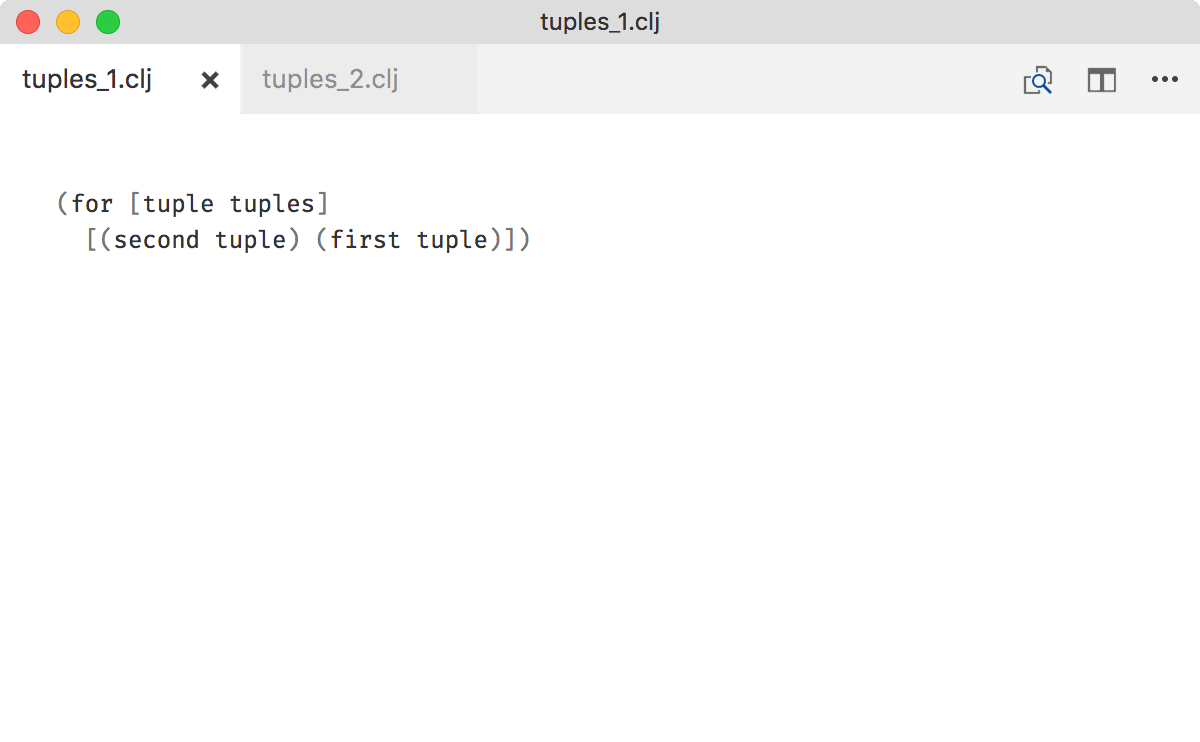
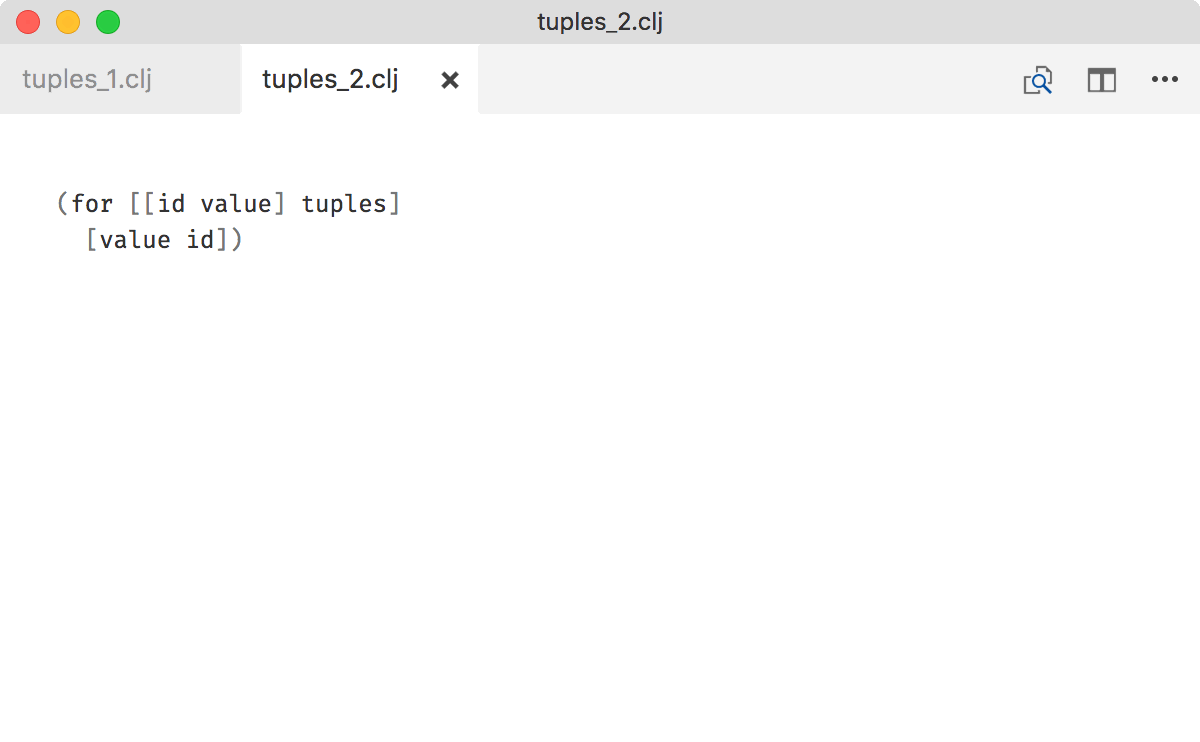
you’re missing an opportunity to use destructuring to
- improve readability,
- assign names to tuple elements
- and show the shape of the data:
Don’t fall for expanded opts
The expanded opts idiom does only two things:
- it is extremely cool,
- and it saves you two curly brackets at the call site.
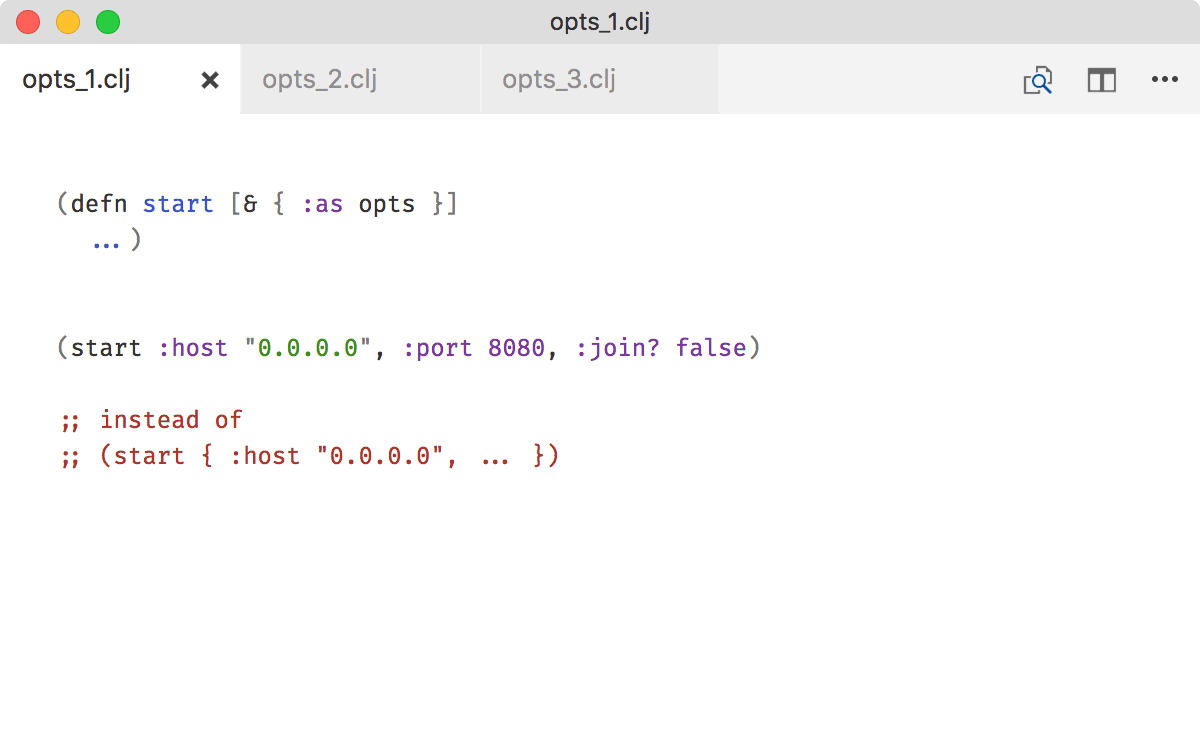
The downsides are much more serious. start will be extremely painful to call if you construct map of options dynamically or if you need to do it through apply:
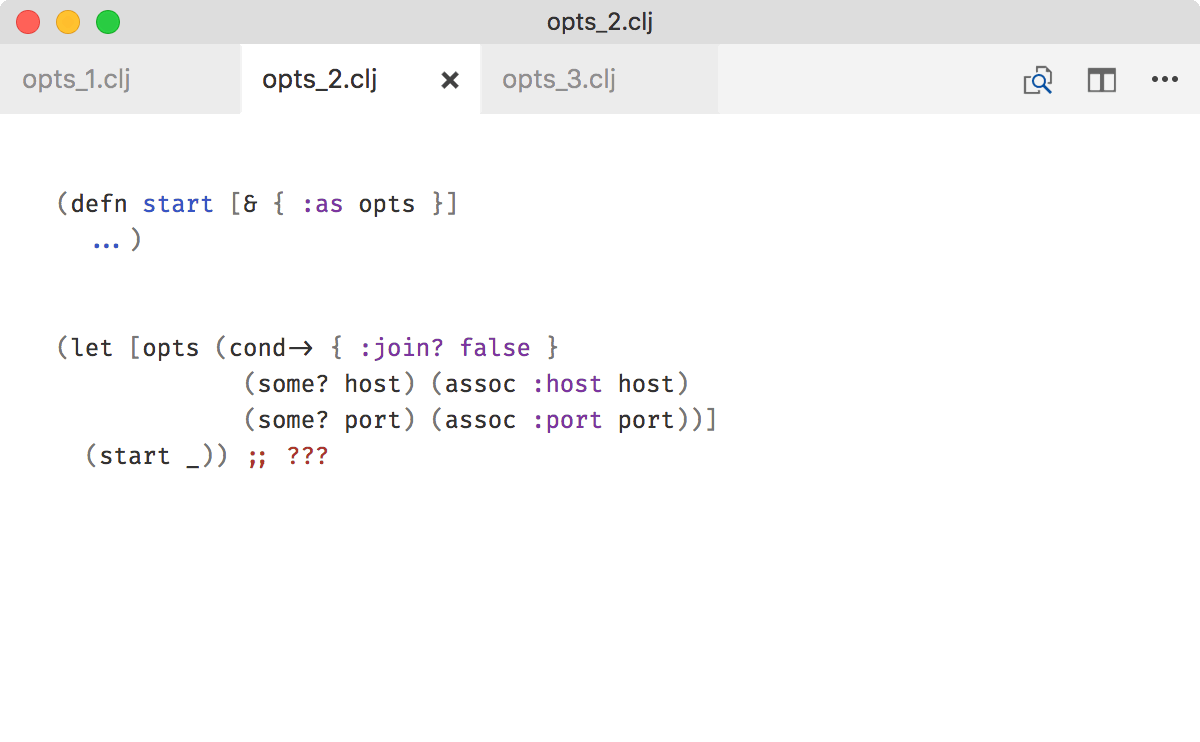
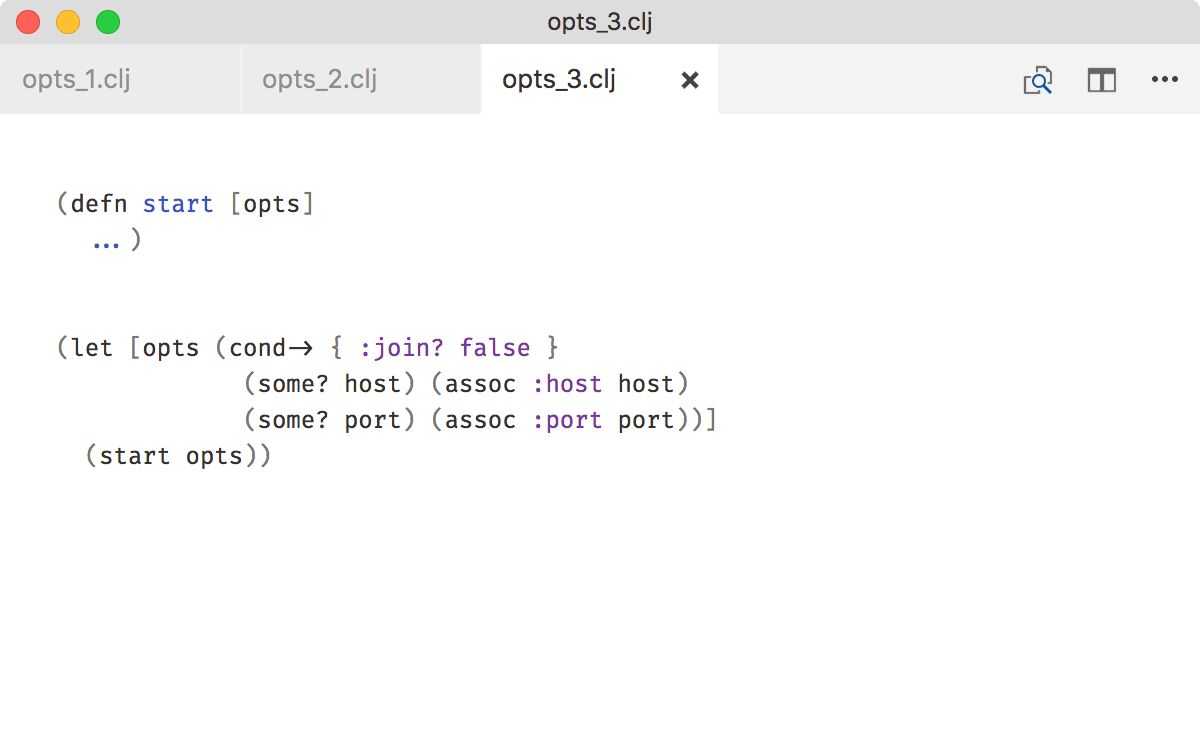
Because of that, I recommend to always accept options as a map:
Use * as prefix for references
References and their content are different, so they need different names. At the same time, they are not that different to invent unique combination of names each time.
I suggest simple convention: prepend * (star) to reference names.
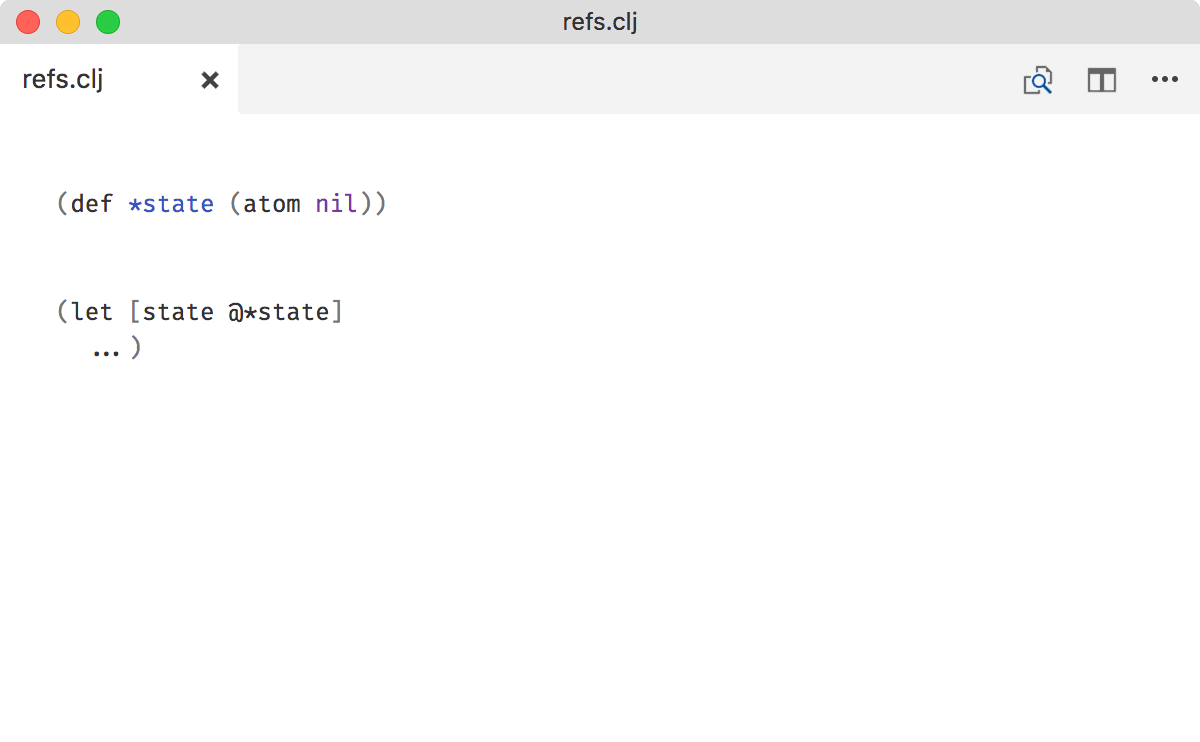
The star was chosen because it resembles C/C++ pointers.
Align let bindings in two columns
Compare this:
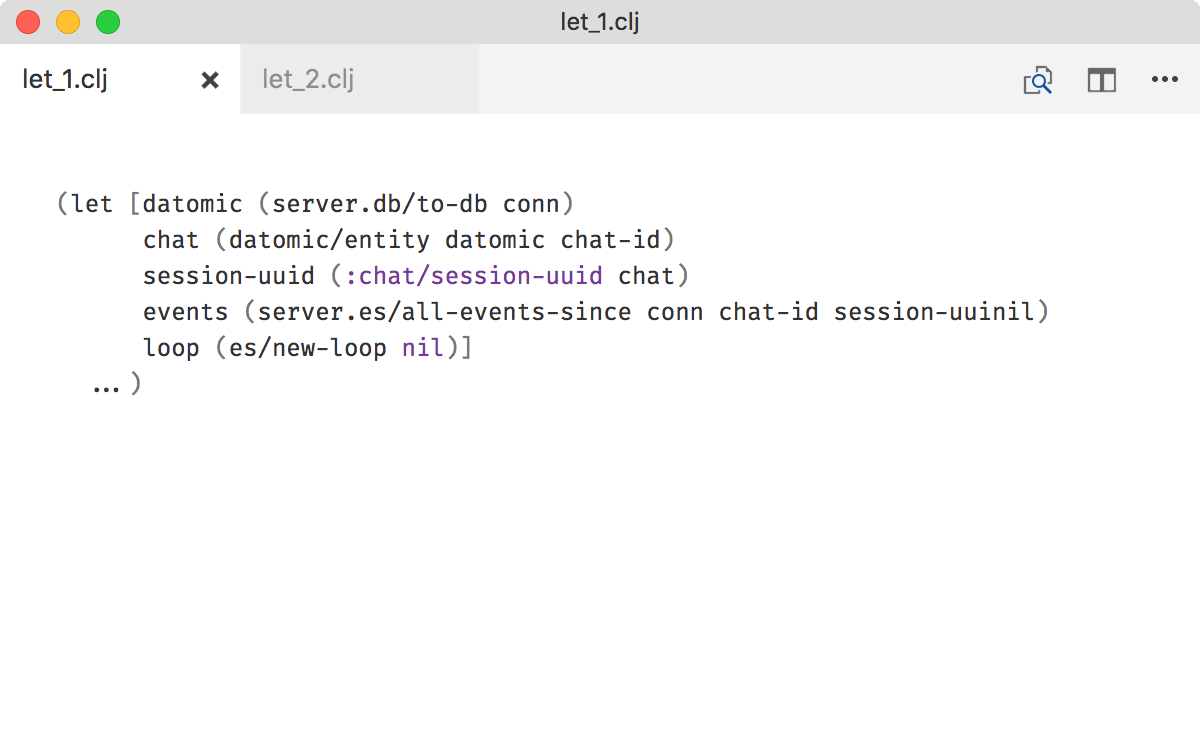
to this:
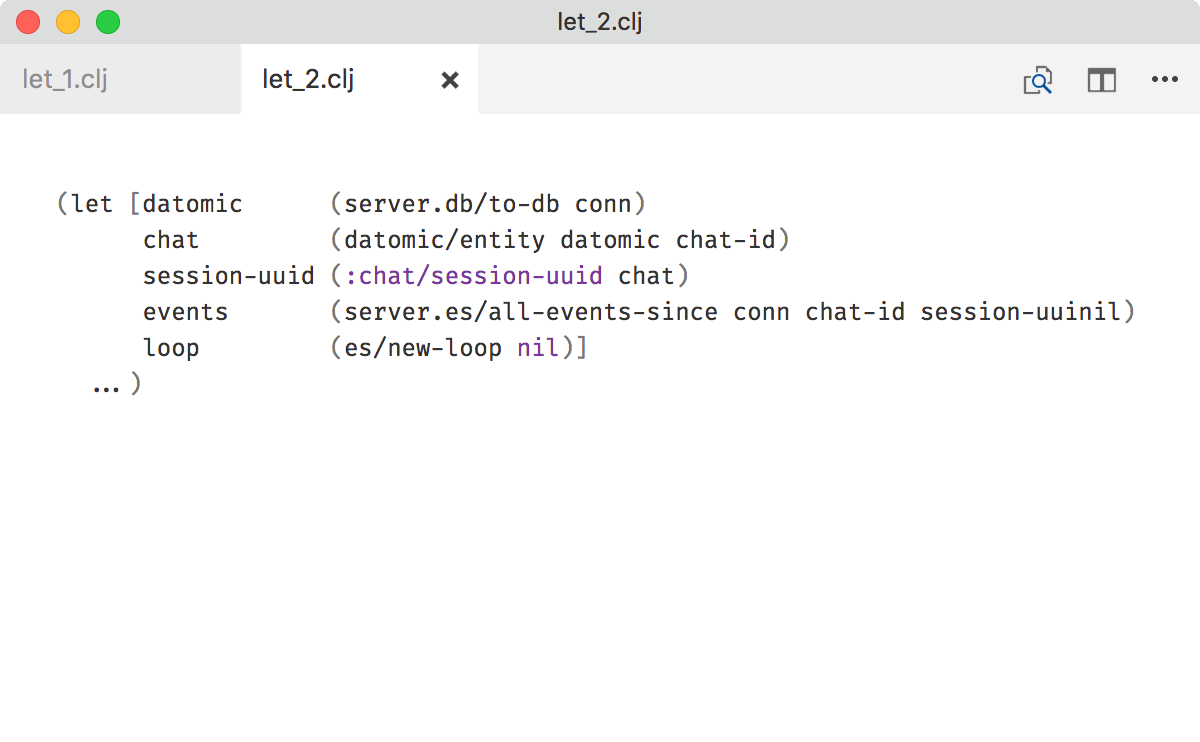
I do it by hand, which I consider to be a small price for readability boost that big. I hope your autoformatter can live with that.
Use two empty lines between top-level forms
Put two empty lines between functions. It’ll give them more space to breathe.

Seems unimportant, but trust me: once you try it, you’ll never want to go back.
Hi!
I’m Nikita. Here I write about programming and UI design Subscribe
I also create open-source stuff: Fira Code, AnyBar, DataScript and Rum. If you like what I do and want to get early access to my articles (along with other benefits), you should support me on Patreon.