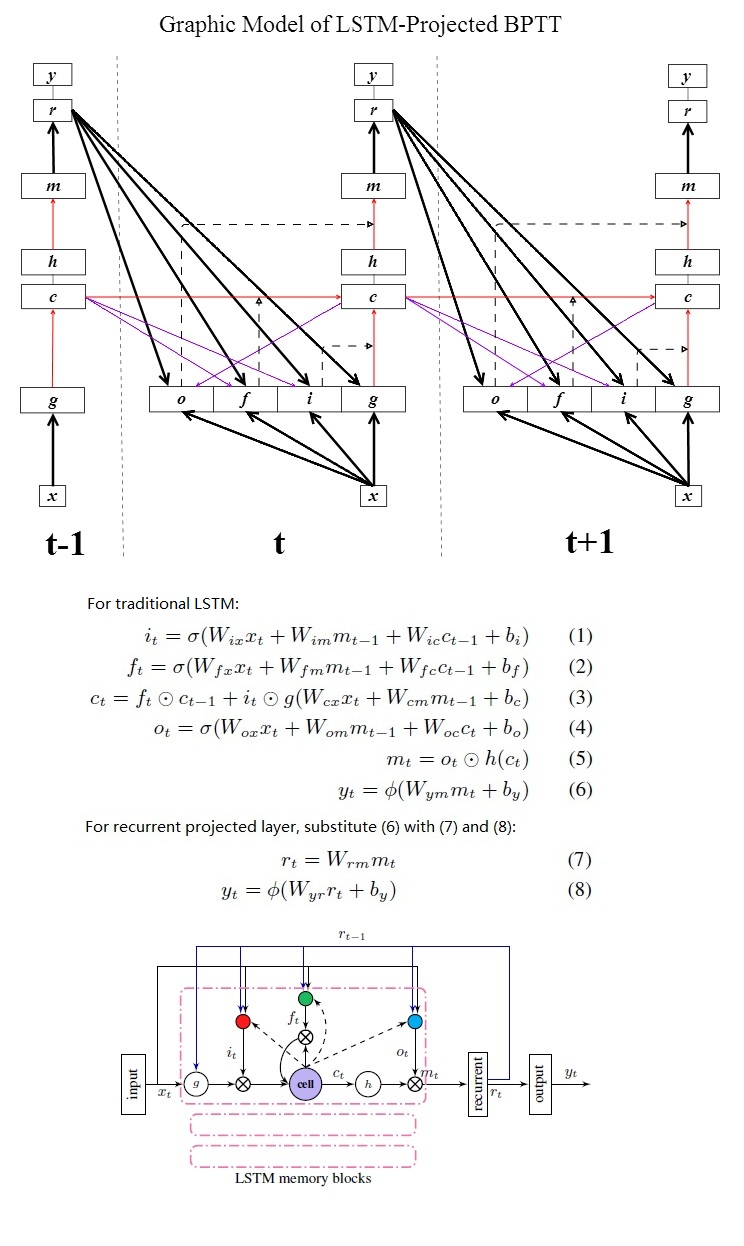
- peephole connection(purple) are diagonal
- output-gate peephole is not recursive
- dashed arrows: adaptive weight, i.e activations of (input gate, forget gate, output gate)
Currently implementation includes two versions:
- standard
Go to sub-directory to get more details.
- Standard version: exactly the same as DNN, feed LSTM nnet into nnet-forward as AM scorer, remember nnet-forward doesn't have a mechanism to delay target, so "time-shift" component is needed to do this.
- Google version:
- convert binary nnet into text format via nnet-copy, and open text nnet with your text editor
- change "Transmit" component to "TimeShift", keep your setup consistent with "--targets-delay" used in nnet-train-lstm-streams
- edit "LstmProjectedStreams" to "LstmProjected", remove "NumStream" tag, now the "google version" is converted to "standard version", and you can perform AM scoring via nnet-forward, e.g:
<Nnet>
<TimeShift> 40 40 <Shift> 5
<LstmProjected> 512 40 <CellDim> 800 [ ...
<AffineTransform> 16624 512 <LearnRateCoef> 1 <BiasLearnRateCoef> 1 <MaxNorm> 0 [ ...
<Softmax> 16624 16624
</Nnet>
In google's paper, two layers of medium-sized LSTM is the best setup to beat DNN on WER. You can do this by text level editing:
- use some of your training data to train one layer LSTM nnet
- convert it into text format with nnet-copy with "--binary=false"
- insert a pre-initialized LSTM component text between softmax and your pretrained LSTM, and you can feed all your training data to the stacked LSTM, e.g:
<Nnet>
<Transmit> 40 40
<LstmProjectedStreams> 512 40 <CellDim> 800 <NumStream> 4 [ ...
<LstmProjectedStreams> 512 512 <CellDim> 800 <NumStream> 4 [ ...
<AffineTransform> 16624 512 <LearnRateCoef> 1 <BiasLearnRateCoef> 1 <MaxNorm> 0 [ ...
<Softmax> 16624 16624
</Nnet>
The key is how you apply "target-delay".
- standard version: the nnet should be trained with "TimeShift" because default nnet1 training tool (nnet-train-frame-shuf & nnet-train-perutt) doesn't provide target delay.
- google version: due to the complexity of multi-stream training, the training tool "nnet-train-lstm-streams" provides an option "--target-delay", so in multi-stream training, a dummy "Transmit" component is used for a trivial reason related to how nnet1 calls Backpropagate(). But in testing time, the google version is first converted to standard version, so the "transmit" should also be switched to "TimeShift" during the conversion.
I implemented the "forward-connection droping out" according another paper from google, but later I didn't implement dropout retention, so the effects of dropout are not tested at all, and I leave it commented out.