Today we are announcing the distributed version of TimescaleDB, which is currently in private beta (public version slated for later this year).
TimescaleDB, a time-series database on PostgreSQL, has been production-ready for over two years, with millions of downloads and production deployments worldwide. Today, for the first time, we are publicly sharing our design, plans, and benchmarks for the distributed version of TimescaleDB.
PostgreSQL is making an undeniable comeback
First released 30+ years ago, PostgreSQL today is making an undeniable comeback. It is the fastest growing database right now, faster than MongoDB, Redis, MySQL, and others. PostgreSQL itself has also matured and broadened in capabilities, thanks to a core group of maintainers and a growing community.
Yet if one main criticism of PostgreSQL exists, it is that horizontally scaling out workloads to multiple machines is quite challenging. While several PostgreSQL projects have developed scale-out options for OLTP workloads, time-series workloads, which we specialize in, represent a different kind of problem.
Problem: time-series workloads are different
Simply put, time-series workloads are different than typical database (OLTP) workloads. This is for several reasons: writes are insert, not update heavy, and those inserts are typically to recent time ranges; reads are typically on continuous time-ranges, not random; writes and reads typically happen independently, rarely in the same transaction. Also, time-series insert volumes tend to be far higher and data tends to accumulate far more quickly than in OLTP. So scaling writes, reads, and storage is a standard concern for time series.
These were the same principles upon which we developed and first launched TimescaleDB two years ago. Since then, developers all over the world have been able to scale a single TimescaleDB node, with replicas for automated failover, to 2 million metrics per second and 10s of terabytes of data storage.
This has worked quite well for the vast majority of our users. But of course, workloads grow and software developers (including us!) always want more. What we need is a distributed system on PostgreSQL for time-series workloads.
Solution: Chunking, not sharding
Our new distributed architecture, which a dedicated team has been hard at work developing since last year, is motivated by a new vision: scaling to over 10 million metrics a second, storing petabytes of data, and processing queries even faster via better parallelization. Essentially, a system that can grow with you and your time-series workloads.
Most database systems that scale-out to multiple nodes rely on horizontally partitioning data by one dimension into shards, each of which can be stored on a separate node.
We chose not to implement traditional sharding for scaling-out TimescaleDB. Instead, we embraced a core concept from our single-node architecture: the chunk. Chunks are created by automatically partitioning data by multiple dimensions (one of which is time). This is done in an fine-grain way such that one dataset may be comprised of 1000s of chunks, even on a single node.
Unlike sharding, which typically only enables scale-out, chunking is quite powerful in its ability to enable a broad set of capabilities. For example:
- Scale-up (on same node) and scale-out (across multiple nodes)
- Elasticity: Adding and deleting nodes by having data grow onto new nodes and age out of old ones
- Partitioning flexibility: Changing the chunk size, or partitioning dimensions, without downtime (e.g., to account for increased insert rates or additional nodes)
- Data retention policies: Deleting chunks older than a threshold
- Data tiering: Moving older chunks from faster, expensive storage to cheaper, slower storage
- Data reordering: Writing data in one order (e.g., by time) based on write patterns, but then rewriting it later in another order (e.g., device_id) based on query patterns
| Shards | Chunks | |
| Creation | Typically manual | Automatic |
| Number | < 10 per node | 100-1000s per node |
| Scale-out | Yes | Yes |
| Scale-up | No | Yes |
| Elasticity | No | Yes |
| Partitioning flexibility | No | Yes |
| Data retention policies | No | Yes |
| Data tiering | No | Yes |
| Data reordering | No | Yes |
A much more detailed discussion is later in this post.
Benchmarks
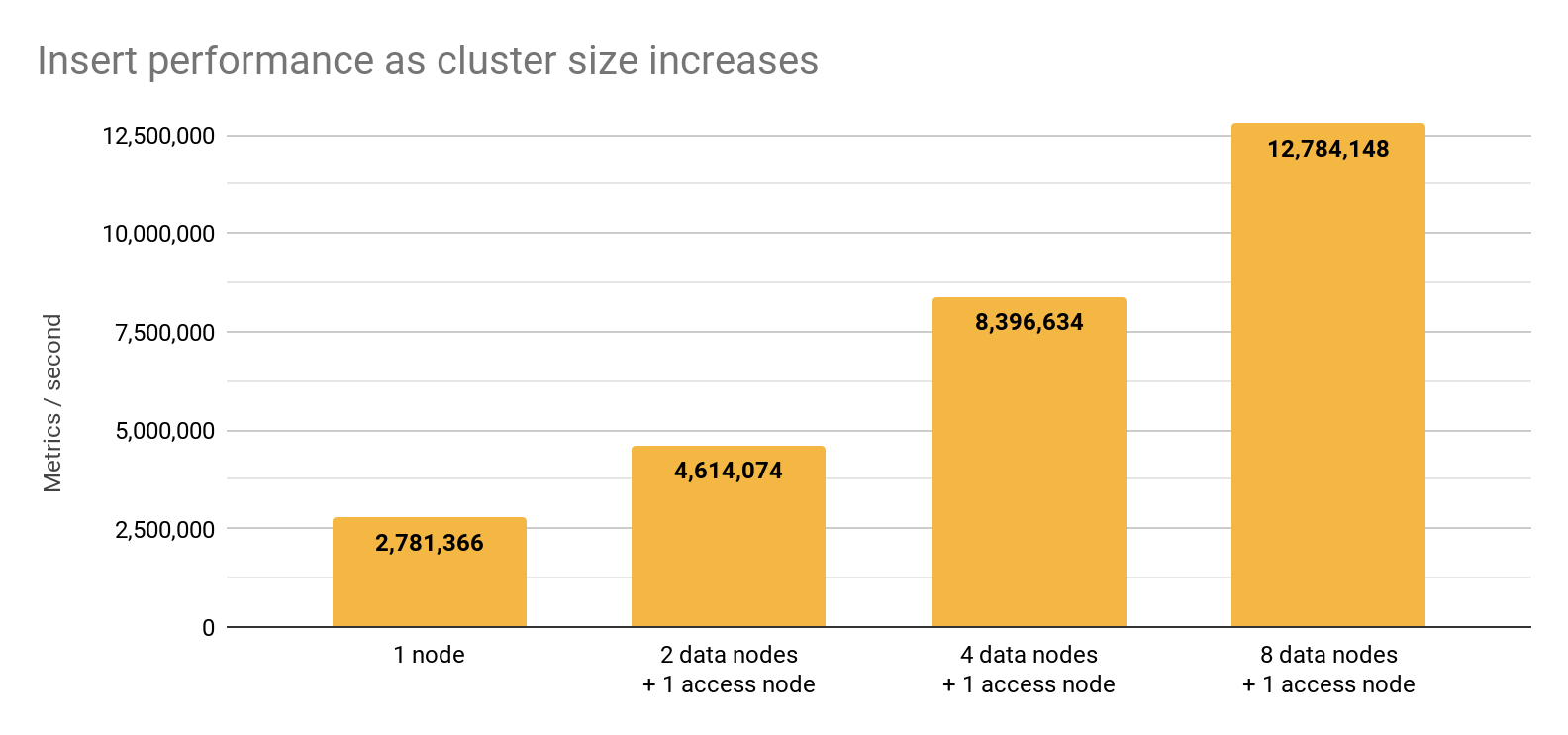
While we plan to start publishing more benchmarks over the next few months, we wanted to share some early results demonstrating our distributed architecture’s ability to sustain high write rates. As you can see, at 9 nodes the system achieves an insert rate well over 12 million metrics a second:
Next steps
This multi-node version of TimescaleDB is currently in private beta. If you’d like to join the private beta, please fill out this form. You can also view the documentation here.
The rest of this post describes the underlying design principles of our distributed architecture and how it works. There is also a FAQ at the end of the post with answers to questions we commonly hear about this architecture.
Please continue reading to learn more.
The five objectives of database scaling
Based on our own experience, combined with our interactions with TimescaleDB users, we have identified five objectives for scaling a database for time-series workloads:
- Total storage volume: Scaling to larger amounts of data under management
- Insert rate: Supporting higher ingestion rates of rows or datapoints per second
- Query concurrency: Supporting larger numbers of concurrent queries, sometimes via data replication
- Query latency: Reducing the latency to access a large volume of data to handle a single query, typically through query parallelization
- Fault tolerance: Storing the same portion of data on multiple servers/disks, with some automation for failover in case of failure
Today, TimescaleDB leverages PostgreSQL streaming replication for primary/replica clustering: There is a single primary node that accepts all writes, which then streams its data (more specifically, its Write Ahead Log) to one or more replicas.
But ultimately, TimescaleDB using PostgreSQL streaming replication requires that each replica store a full copy of the dataset, and the architecture maxes out its ingest rate at the primary’s write rate and its query latency at a single node’s CPU/IOPS rate.
While this architecture has worked well so far for our users, we can do even better.
Designing for Scale
In computer science, the key to solving big problems is breaking them down into smaller pieces and then solving each of those sub-problems, preferably, in parallel.
In TimescaleDB, chunking is the mechanism by which we break down a problem and scale PostgreSQL for time-series workloads. More specifically, TimescaleDB already automatically partitions a table across multiple chunks on the same instance, whether on the same or different disks. But managing lots of chunks (i.e., “sub-problems”) can also be a daunting task so we came up with the hypertable abstraction to make partitioned tables easy to use and manage.
Now, in order to take the next step and scale to multiple nodes, we are adding the abstraction of a distributed hypertable. Fortunately, hypertables extend naturally to multiple nodes: instead of creating chunks on the same instance, we now place them across different instances.
Still, distributed hypertables pose new challenges in terms of management and usability when operating at scale. To stay true to everything that makes hypertables great, we carefully designed our system around the following principles.
Design Principles
- Use existing abstractions: Hypertables and chunking extend naturally to multiple nodes. By building on these existing abstractions, together with existing PostgreSQL capabilities, we provide a robust and familiar foundation for scale-out clustering.
- Be transparent: From a user's perspective, interacting with distributed hypertables should be akin to working with regular hypertables, e.g., familiar environment, commands, functionality, metadata, and tables. Users need not be aware that they are interacting with a distributed system and should not need to take special actions when doing so (e.g., application-aware shard management).
- Scale access and storage independently: Given that access and storage needs vary across workloads (and time), the system should be able to scale access and storage independently. One way of doing this is via two types of database nodes, one for external access (“access node”) and another for data storage (“data node”).
- Be easy to operate: A single instance should be able to function as either an access node or data node (or even both at the same time), with sufficient metadata and discovery to allow each node to play its necessary role.
- Be easy to expand: It should be easy to add new nodes to the system to increase capacity, including upgrading from a single-node deployment (in which a single instance should seamlessly become a data node in a multi-node deployment).
- Provide flexibility in data placement: The design should account for data replication and enable the system to have significant flexibility in data placement. Such flexibility can support collocated JOIN optimizations, heterogeneous nodes, data tiering, AZ-aware placement, and so forth. An instance serving as an access node should also be able to act as a data node, as well as store non-distributed tables.
- Support production deployments: The design should support high-availability deployments, where data is replicated across multiple servers and the system automatically detects and transparently recovers from any node failures.
Now, let’s understand how our distributed architecture begins to follow these principles in practice.
Introducing Distributed Hypertables
Following the above design principles, we built a multi-node database architecture that allows hypertables to distribute across many nodes to achieve greater scale and performance.
Users interact with distributed hypertables in much the same way as they would with a regular hypertable (which itself looks just like a regular Postgres table). As a result, inserting data into or querying data from a distributed hypertable looks identical to doing that with a standard table.
For instance, let’s consider a table with the following schema:
CREATE TABLE measurements ( time TIMESTAMPTZ NOT NULL, device_id TEXT NOT NULL, temperature DOUBLE PRECISION NULL, humidity DOUBLE PRECISION NULL
);
This table is turned into a distributed hypertable by partitioning on both the time and device_id columns:
SELECT create_distributed_hypertable(‘measurements’, ‘time’, ‘device_id’);Following this command, all the normal table operations still work as expected: inserts, queries, schema modifications, etc. Users do not have to worry about tuple routing, chunk (partition) creation, load balancing, and failure recovery: the system handles all these concerns transparently. In fact, users can convert their existing hypertables into distributed hypertables by seamlessly incorporating their standalone TimescaleDB instance into a cluster.
Now let’s look at the architecture that makes all of this possible.
Architecture: Access nodes and Data nodes
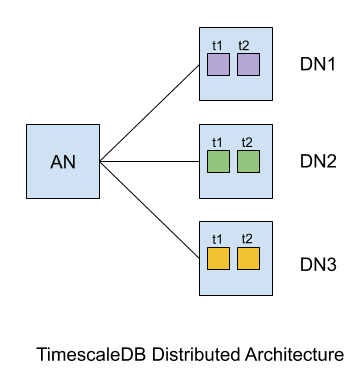
At a high-level, our distributed database architecture consists of access nodes, to which clients connect, and data nodes where data for the distributed hypertable resides. (While we are initially focused on supporting a single access node with optional read replicas, our architecture will extend to a logically distributed access node in the future.)
Both types of nodes run the same TimescaleDB/PostgreSQL stack, although in different configurations. In particular, an access node needs metadata (e.g., catalog information) to track state across the database cluster, such as the nodes in the cluster and where data resides (stored as “chunks”), so that the access node can insert data on the nodes that have matching chunks and perform query planning to exclude chunks, and ultimately entire nodes, from a query. While the access node has lots of knowledge about the state of the distributed database, data nodes are “dumb”: they are essentially single node instances that can be added and removed using simple administrative functions on the access node.
The main difference in creating distributed hypertables compared to regular hypertables, however, is that we recommend having a secondary “space” partitioning dimension. While not a strict requirement, the additional “space” dimension ensures that data is evenly spread across all the data nodes when a table experiences (roughly) time-ordered inserts.
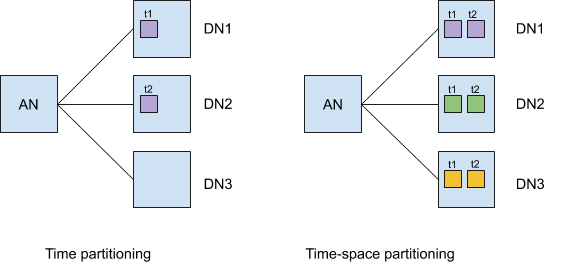
The advantage of a multi-dimensional distributed hypertable is illustrated in the figure above. With time-only partitioning, chunks for two time intervals (t1 and t2) are created on data nodes DN1 and DN2, in that order. While with multi-dimensional partitioning, chunks are created along the space dimension on different nodes for each time interval. Thus, inserts to t1 are distributed across multiple nodes instead of just one of them.
Question: Isn’t this just traditional sharding?
Not really. While many of our goals are achieved by traditional (single dimensional) “database sharding” approaches (where the number of shards are proportional to the number of servers), distributed hypertables are designed for multi-dimensional chunking with a large number of chunks (from 100s to 10,000s), offering more flexibility in how chunks are distributed across a cluster. On the other hand, traditional shards are typically pre-created and tied from the start to individual servers. Thus, adding new servers to a sharded system is often a difficult and disruptive process that might require redistributing (and locking) large amounts of data.
By contrast, TimescaleDB’s multi-dimensional chunking auto-creates chunks, keeps recent data chunks in memory, and provides time-oriented data lifecycle management (e.g., for data retention, reordering, or tiering policies).
Within a multi-node context, fine-grain chunking also:
- Increases aggregate disk IOPS by parallelizing operations across multiple nodes and disks
- Horizontally balances query load across nodes
- Elastically scales out to new data nodes
- Replicates data for fault tolerance and load balancing
Chunks are automatically created and sized according to the current partitioning configuration. This can change over time: i.e., a new chunk can be sized or divided differently from a prior one, and both can coexist in the system. This allows a distributed hypertable to seamlessly expand to new data nodes, by writing recent chunks in a new partitioning configuration that covers additional nodes, without affecting existing data or requiring lengthy locking. Together with a retention policy that eventually drops old chunks, the cluster will rebalance over time, as shown in the figure below.
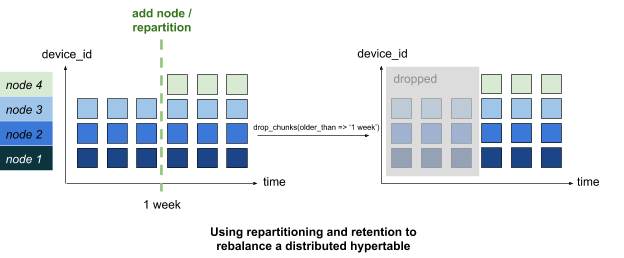
This is a much less disruptive process than in a similar sharded system since read locks are held on smaller chunks of data at a time.
One might think that chunking puts additional burden on applications and developers. However, applications in TimescaleDB do not interact directly with chunks (and thus do not need to be aware of this partition mapping themselves, unlike in some sharded systems), nor does the system expose different capabilities for chunks than the entire hypertable (e.g., in a number of other storage systems, one can execute transactions within shards but not across them).
To illustrate that this is the case, let’s look at how distributed hypertables work internally.
How it works: the life of a request (insert or query)
Having learned about how to create distributed hypertables and the underlying architecture, let's look into the "life of a request", to better understand the interactions between the access node and data nodes.
Inserting data
In the following example, we will continue to use the “measurements” table we introduced earlier. To insert data into this distributed hypertable, a single client connects to the access node and inserts a batch of values as normal. Using a batch of values is preferred over row-by-row inserts in order to achieve higher throughput. Such batching is a very common architectural idiom, e.g., when ingesting data into TimescaleDB from Kafka, Kinesis, IoT Hubs, or Telegraf.
INSERT INTO measurements VALUES (‘2019-07-01 00:00:00.00-05’, ‘A001’, 70.0, 50.0), (‘2019-07-01 00:00:00.10-05’, ‘B015’, 68.5, 49.7), (‘2019-07-01 00:00:00.05-05’, ‘D821’, 69.4, 49.9), (‘2019-07-01 00:00:01.01-05’, ‘A001’, 70.1, 50.0);Since “measurements” is a distributed hypertable, the access node doesn’t insert these rows locally like it would with a regular hypertable. Instead, it uses its catalog information (metadata) to ultimately determine the set of data nodes where the data should be stored. In particular, for new rows to be inserted, it first uses the values of the partitioning columns (e.g., time and device_id) to map each row to a chunk, and then determines the set of rows that should be inserted into each chunk, as shown in the figure below.
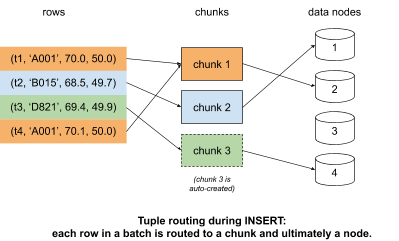
If an appropriate chunk does not yet exist for some of the rows, TimescaleDB will create new chunk(s) as part of the same insert transaction, and then assign each new chunk to at least one data node. The access node creates and assigns new chunks along the “space” dimension (device_id), if such a dimension exists. Thus, each data node is responsible for only a subset of devices, but all of them will take on writes for the same time intervals.
After the access node has written to each data node, it then executes a two-phase commit of these mini-batches to the involved data nodes so that all data belonging to the original insert batch is inserted atomically within one transaction. This also ensures that all the mini-batches can be rolled back in case of a failure to insert on one of the data nodes (e.g., due to a data conflict or failed data node).
The following shows the part of the SQL query that an individual data node receives, which is a subset of the rows in the original insert statement.
INSERT INTO measurements VALUES (‘2019-07-01 00:00:00.00-05’, ‘A001’, 70.0, 50.0), (‘2019-07-01 00:00:01.01-05’, ‘A001’, 70.1, 50.0); Leveraging PostgreSQL EXPLAIN information
One nice thing about how TimescaleDB carefully ties into the PostgreSQL query planner is that it properly exposes EXPLAIN information. You can EXPLAIN any request (such as the INSERT requests above) and get full planning information:
EXPLAIN (costs off, verbose)
INSERT INTO measurements VALUES
('2019-07-01 00:00:00.00-05', 'A001', 70.0, 50.0),
('2019-07-01 00:00:00.10-05', 'B015', 68.5, 49.7),
('2019-07-01 00:00:00.05-05', 'D821', 69.4, 49.9),
('2019-07-01 00:00:01.01-05', 'A001', 70.1, 50.0); QUERY PLAN
---------------------------------------------------------------------------------------- Custom Scan (HypertableInsert) Insert on distributed hypertable public.measurements Data nodes: data_node_1, data_node_2, data_node_3 -> Insert on public.measurements -> Custom Scan (DataNodeDispatch) Output: "*VALUES*".column1, "*VALUES*".column2, "*VALUES*".column3, "*VALUES*".column4 Batch size: 1000 Remote SQL: INSERT INTO public.measurements("time", device_id, temperature, humidity) VALUES ($1, $2, $3, $4), ..., ($3997, $3998, $3999, $4000) -> Custom Scan (ChunkDispatch) Output: "*VALUES*".column1, "*VALUES*".column2, "*VALUES*".column3, "*VALUES*".column4 -> Values Scan on "*VALUES*" Output: "*VALUES*".column1, "*VALUES*".column2, "*VALUES*".column3, "*VALUES*".column4
(12 rows)In PostgreSQL, plans like the above one are trees where every node produces a tuple (row of data) up the tree when the plan is executed. Essentially, a parent, which is sourced at the root, asks for new tuples until no more tuples can be produced. In this particular insert plan, tuples originate at the ValueScan leaf node, which generates a tuple from the original insert statement whenever the ChunkDispatch parent asks for one. Whenever ChunkDispatch reads a tuple from its child, it “routes” the tuple to a chunk, and creates a chunk on a data node if necessary. The tuple is then handed up the tree to DataNodeDispatch that buffers the tuple in a per-node buffer as given by the chunk routed to in the previous step (every chunk has one or more associated data nodes responsible for the chunk). DataNodeDispatch will buffer up to 1000 tuples per data node (configurable) until it flushes a buffer using the given remote SQL. The servers involved are shown in the EXPLAIN, although not all of them might ultimately receive data since the planner cannot know at plan time how tuples will be routed during execution.
It should be noted that distributed hypertables also support COPY for further performance during inserts. Inserts using COPY do not execute a plan, like the one shown for INSERT above. Instead, a tuple is read directly from the client connection (in COPY mode) and then routed to the corresponding data node connection (also in COPY mode). Thus, tuples are streamed to data nodes with very little overhead. However, while COPY is suitable for bulk data loads, it does not support things like RETURNING clauses and thus has limitations that prohibit its use in all cases.
Querying data
Read queries on a distributed hypertable follow a similar path from access node to data nodes. A client makes a standard SQL request to an access node:
SELECT time_bucket('1 minute', time) as minute, device_id, min(temp), max(temp), avg(temp)
FROM measurements
WHERE device_id IN ('A001', 'B015')
AND time > NOW() - interval '1 hour'
GROUP BY minute, device_id;Making this query performant on distributed hypertables relies on three tactics:
- Limiting the amount of work,
- Optimally distributing and pushing down work to data nodes, and
- Executing in parallel across the data nodes
TimescaleDB is designed to implement these tactics. However, given the length of this post so far, we’ll cover these topics in an upcoming article.
What’s next?
Selected users and customers have already been testing distributed TimescaleDB in private beta, and we plan to make an initial version of it more widely available later this year. It will support most of the good properties described above (high write rates, query parallelism and predicate push down for lower latency), as well as some others that we will describe in future posts (elastically growing a cluster to scale storage and compute, and fault tolerance via physical replica sets).
If you’d like to join the private beta, please fill out this form. You can also view the documentation here.
And if the challenge of building a next-generation database infrastructure is of interest to you, we’re hiring worldwide and always looking for great engineers to join the team.
FAQ
Q: What about query performance benchmarks? What about high-availability, elasticity, and other operational topics?
Given the length of this post so far, we opted to cover query performance benchmarks, how our distributed architecture optimizes queries, as well as operational topics, in future posts.
Q: How will multi-node TimescaleDB be licensed?
We'll announce licensing when multi-node TimescaleDB is more publicly available.
Q: Why didn’t you use [fill in the blank] scale-out PostgreSQL option?
While there are existing options for scaling PostgreSQL to multiple nodes, we found that none of them provided the architecture and data model needed to enable scaling, performance, elasticity, data retention policies, etc, for time-series data.
Put another way, we found that by treating time as a first-class citizen in a database architecture, one can enable much better performance and a vastly superior user experience. We find this true for single-node as well as for multi-node. In addition, there are many more capabilities we want to implement, and often these integrate closely into the code. If we didn’t write the code ourselves with these in mind, it would have been quite challenging, if not impossible.
Q: How does this fit into the CAP Theorem?
Any discussion of a distributed database architecture should touch on the CAP Theorem. As a quick reminder, CAP states that there's an implicit tradeoff between strong Consistency (Linearizability) and Availability in distributed systems, where availability is informally defined as being able to immediately handle reads and writes as long as any servers are alive (regardless of the number of failures). The P states that the system is able to handle partitions, but this is a bit of a misnomer: You can design your system to ultimately provide Consistency or Availability, but you can’t ultimately control whether failures (partitions) happen. Even if you try really hard through aggressive network engineering to make failures rare, failures still occasionally happen, and any system must then be opinionated for C or A. And if you always want Availability, even if partitions are rare (so that the system can, in the normal case, provide stronger consistency), then applications must still suffer the complexity of handling inconsistent data for the uncommon case.
The summary: TimescaleDB doesn’t overcome the CAP Theorem. We do talk about how TimescaleDB achieves “high availability”, using the term as commonly used in the database industry to mean replicated instances that perform prompt and automated recovery from failure. This is different than formal “Big A” Availability from the CAP Theorem, and TimescaleDB today sacrifices Availability for Consistency under failure conditions.
Time-series workloads introduce an interesting twist to this discussion, however. We’ve talked about how their write workloads are different (inserts to recent time ranges, not random updates), and how this pattern leads to different possibilities for elasticity (and reduced write amplification). But we also see a common idiom across architectures integrating TimescaleDB, whereby the write and read data paths are performed by different applications. We rarely see read-write transactions (aside from upserts). While queries help drive dashboards, reporting/alerting, or other real-time analytics, data points are often ingested from systems like Kafka, NATS, MQTT brokers, IoT Hubs, or other eventing/logging systems. These upstream systems are typically built around buffering, which greatly ameliorate availability issues if the system temporarily blocks writes (which any “C” system must do): these upstream systems will just buffer and retry upon automated recovery.
So in short, technically TimescaleDB is a CP system that sacrifices A under failure conditions. But in practice we find that, because of upstream buffers, this generally is much less an issue.